When someone talks about AI, or machine learning, or deep convolutional networks, what they’re really talking about is — as is the case for so many computing concepts — a lot of carefully manicured math. At the heart of these versatile and powerful networks is a volume of calculation only achievable by the equivalent of supercomputers. More than anything else, this computational cost is what is holding back applying AI in devices of comparatively little brain: phones, embedded sensors, cameras.
If that cost could be cut by a couple orders of magnitude, AI would be unfettered from its banks of parallel processors and free to inhabit practically any device — which is exactly what a breakthrough at the Allen Institute for AI makes possible.
XNOR.ai is, essentially, a bit of clever computer-native math that enables AI-like models for vision, speech recognition, to run practically anywhere. It has the potential to be transformative for the industry.
“There’s a disconnect between state of the art AI and common computing,” explained Ali Farhadi, senior research manager on the project at AI2, as they call the place. Nestled on the waterfront nearby Gasworks Park in Seattle, AI2 is focused on “AI for the common good”; it’s small, yet even so is the largest not-for-profit AI research institution in the country.
Machine learning, Farhadi continued, tends to rely on convolutional neural networks; these involve repeatedly performing simple but extremely numerous operations on good-sized matrices of numbers. But because of the nature of the operations, many have to be performed serially rather than in parallel. (Whether machine learning models truly constitute AI is another, so far unanswered question, but for now we’ll use AI in its broader sense.)
For example: it’s simple to multiply each in a set of a thousand numbers by two, since all those operations are independent from one another and can be performed at the same time by a thousand processors or threads working in parallel.
But imagine each operation depends on the result of the previous one — you need to add the last digit of the product of the previous operation to the next one, say. That means you have to go through one by one, which means only one processor can work on it — which means it could take a thousand times as long as the other one, even though really, it’s still simple arithmetic. (I’m oversimplifying, but this is the essential nature of the problem.)
It’s the unfortunate reality of both training and running the machine learning systems performing all these interesting feats of AI that they phenomenally computationally expensive.
Where’s the beef?
“It’s hard to scale when you need that much processing power,” Farhadi said. Even if you could fit the “beefy” — his preferred epithet for the GPU-packed servers and workstations to which machine learning models are restricted — specs into a phone, it would suck the battery dry in a minute. Meanwhile, the accepted workaround is almost comically clumsy when you think about it: you take a load of data you want to analyze, send it over the internet to a datacenter where the AI actually lives, and computers perhaps a thousand miles away work at top speed to calculate the result, hopefully getting back to you within a second or two.
It’s not such a problem if you don’t need that result right away, but imagine if you had to do that in order to play a game on the highest graphical settings; you want to get those video frames up ASAP, and it’s impractical (not to mention inelegant) to send them off to be resolved remotely. But improvements to both software and hardware have made it unnecessary, and our ray-traced shadows and normal maps are applied without resorting to distant datacenters.
Farhadi and his team wanted to make this possible for more sophisticated AI models. But how could they cut the time required to do billions of serial operations?
“We decided to binarize the hell out of it,” he said. By simplifying the mathematical operations to rough equivalents in binary operations, they could increase the speed and efficiency with which AI models can be run by several orders of magnitude.
Here’s why. Even the simplest arithmetic problem involves a great deal of fundamental context, since transistors don’t natively understand numbers — only on and off states. 6 minus 4 is certainly 2, but in order to arrive at that, you have to define 6, 4, 2, and all the numbers in between, what minus means, how to check the work to make sure it’s correct, and so on. It requires quite a bit of logic, literally, to be able to arrive at this simple result.
But chips do have some built-in capabilities, notably a set of simple operations known as logic gates. One gate might take an input, 1 (at this scale, it’s not actually a number but a voltage), and output a 0, or vice versa. That would be a simple NOT gate, also known as an inverter. Or of two inputs, if either is a 1, it outputs a 1 — but if neither or both is a 1, it outputs a 0. That’s an XOR gate.
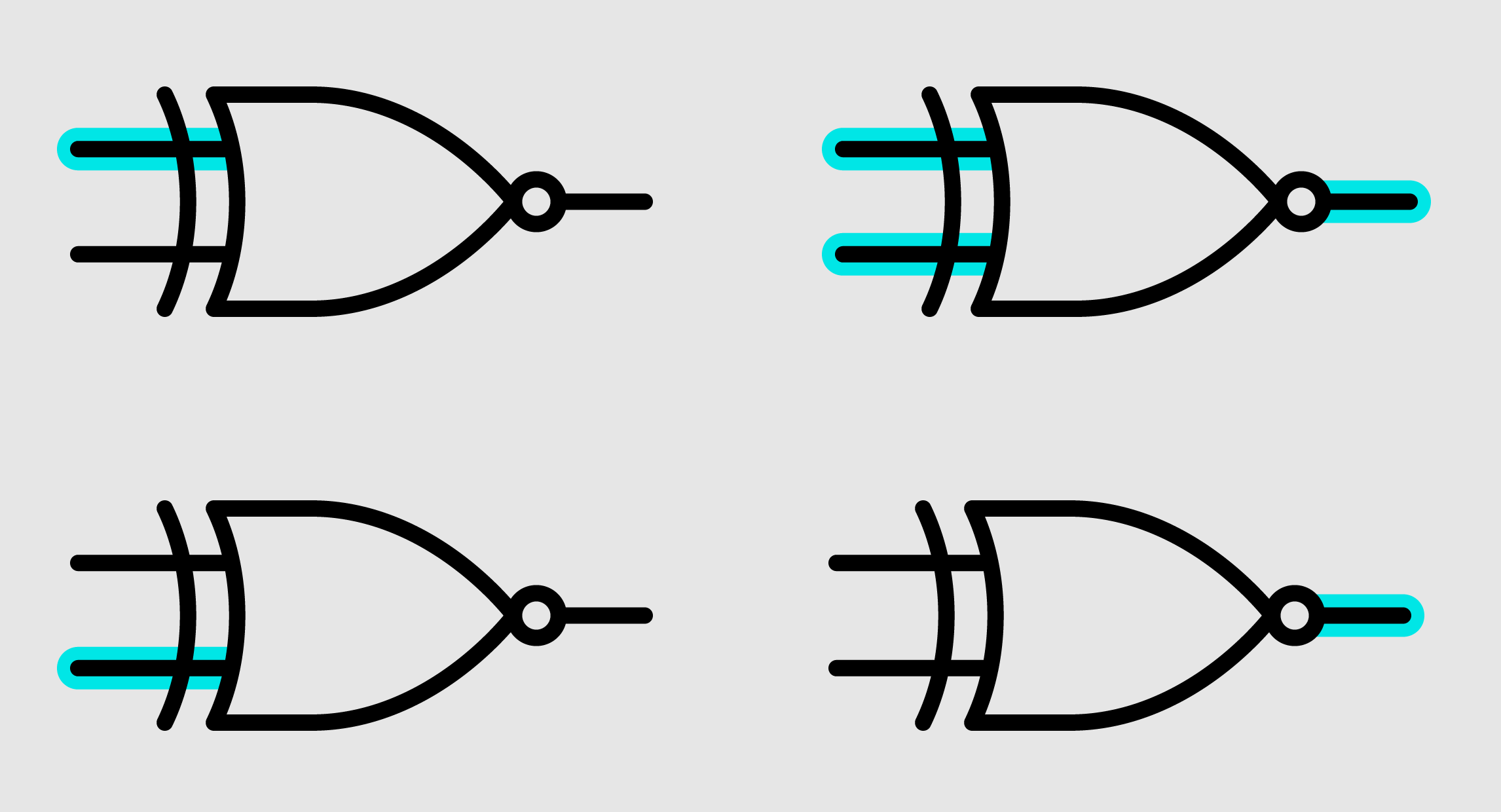
An XNOR gate like this one sends a 1 if the voltage of its inputs matches, and a 0 if they don’t.
These simple operations are carried out at the transistor level and as such are very fast. In fact, they’re pretty much the fastest calculations a computer can do, and it happens that huge arrays of numbers can be subjected to this kind of logic at once, even on ordinary processors.
The problem is it’s not easy to frame complex math in terms that can be resolved by logic gates alone. And it’s harder still to create an algorithm that converts mathematical operations to binary ones. But that’s exactly what the AI2 engineers did.
The 1 percent
Farhadi showed me the fruits of their labor by opening an app on his phone and pointing it out the window. The view of the Fremont cut outside was instantly overlaid with boxes dancing over various objects: boat, car, phone, their labels read. In a way it was underwhelming: after all, this kind of thing is what we see all the time in blog posts touting the latest in computer vision.
But those results are achieved with the benefit of supercomputers and parallelized GPUs; who knows how long it takes a state of the art algorithm to look at an image and say, “there are 6 boats, 2 cars, a phone, and a bush,” as well as label their boundaries. After all, it not only has to go over the whole scene pixel by pixel, but identify discrete objects within it and their edges, compare those to known shapes, and so on; even rudimentary object recognition is a surprisingly complex task for computer vision systems.
This prototype app, running on an everyday smartphone, was doing it 10 times a second.
“You could leave this running for hours on your phone,” Farhadi said, “and we haven’t even optimized it for battery drain.” It’s doing the work of supercomputers, but drawing no more power than a game, and only using a single core of the CPU. A few moments later they showed me real-time object recognition running on a Raspberry Pi Zero, among the simplest and cheapest modern computers available. It was even up on a HoloLens.
They call it XNOR.ai, after the logic gates that power its efficiency.
Now, this isn’t a miracle technology; It’s a compromise between efficiency and accuracy. What the team realized was that CNN calculations don’t have to be exact, because the results are confidence levels, not exact values. A neural network trained to recognize a boat doesn’t arrive at a single numerical value corresponding to “BOAT.” It just does the math and finds that, while the values shown have a 55 percent similarity to those of a duck, they have an 84 percent similarity to those of a boat. So, boat it is. Probably.
 The team felt sure that the operations resulting in these confidence ratings — probably a boat, but possibly a duck — could be replicated in a simpler way (i.e. binarized) without losing too much accuracy. Simplifying the math might do away with 99 percent of the data, Farhadi said, but that’s not a problem if the 1 percent you keep is the only 1 percent that matters. The trouble is figuring out which 1 percent to keep.
The team felt sure that the operations resulting in these confidence ratings — probably a boat, but possibly a duck — could be replicated in a simpler way (i.e. binarized) without losing too much accuracy. Simplifying the math might do away with 99 percent of the data, Farhadi said, but that’s not a problem if the 1 percent you keep is the only 1 percent that matters. The trouble is figuring out which 1 percent to keep.
The cast-away data would help with the confidence, but it isn’t absolutely necessary; you’d lose 5 percent of your accuracy, but get your results 10,000 percent faster. That’s about the nature of the trade-off made by XNOR.ai.
We didn’t go into the specifics of how this binarization — if that’s the word — was achieved, and I don’t suppose I would have understood if we did. The algorithm (or set of them) that converts CNN’s serial math to binary logic is the team’s secret sauce, Farhadi said.
Spinning off
XNOR.ai has about a billion applications: object recognition on extremely low-power devices like security cameras, sorting and tagging photos on your phone, accurate local speech recognition and synthesis, and countless other CPU-intensive processes. It could lead to a fundamental shift in the capabilities of many classes of electronics, in the home and in industry.
AI2’s other projects, generally aimed at replicating human intelligence one way or another, have had their source code regularly released and updated, and to begin with XNOR.ai was no different: the code is available on Github and some employees have already split off their own projects from it.
But while the research is open access and the code is free to download, that doesn’t make it a piece of cake to apply to your own project or device. AI2, being a nonprofit, can’t easily do the licensing and support that a potentially major product like this demands. So XNOR.ai is being spun off as a separate company of the same name.
“AI2 has and will continue to spin-off exciting startups to enable AI technologies we develop to see maximum impact,” AI2 CEO Oren Etzioni said in a statement to TechCrunch. “With XNOR.ai, we feel that commercialization is the best path to seeing the technology reach it’s full potential.”
The new company is in charge of the IP and a revenue-sharing model is in place, though AI2 declined to provide further details. It’s not the first spin-off from AI2 — KITT.ai, a natural language processing platform, jumped ship last year with some VC funding — but it is a somewhat different strategy.
It’s impossible to predict how successful XNOR.ai will be, but I’m convinced that the approach it takes is an incredibly powerful one for putting machine learning to work outside its current confines. We’ll be watching the new startup closely — as well as its inevitable competitors.
Featured Image: Bryce Durbin / TechCrunch



