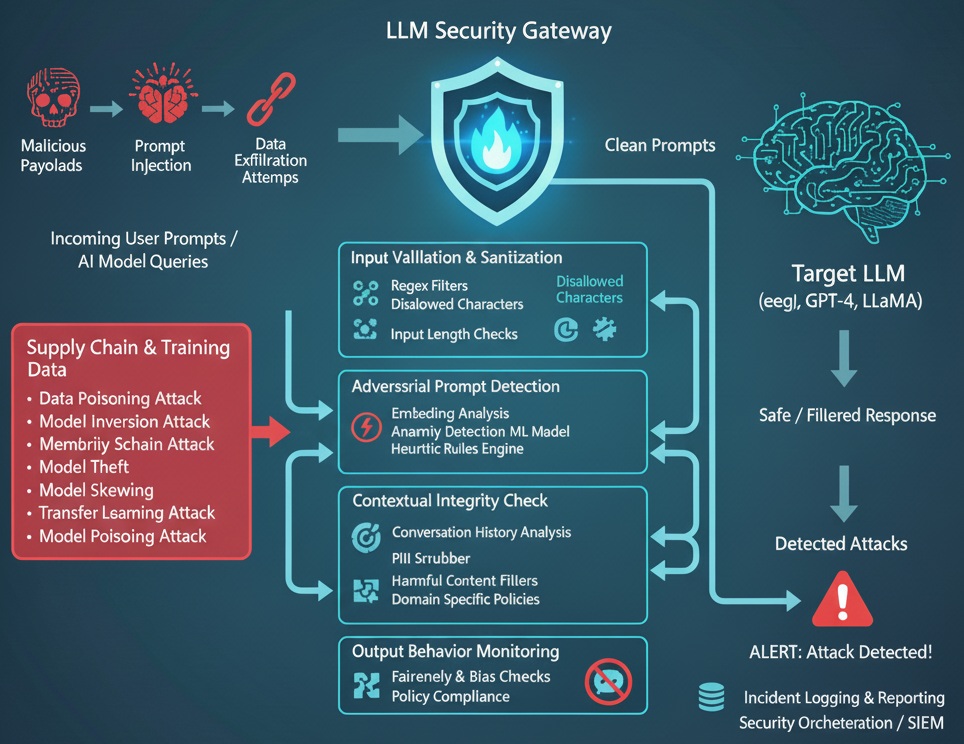
A Large Language Model (LLM) Firewall is a next-generation security mechanism purpose-built to safeguard AI systems, digital infrastructures, and end users from malicious or unintended interactions with advanced generative models such as ChatGPT, GPT-4, and similar LLMs. Just as traditional firewalls regulate network traffic to block unauthorized access, the LLM firewall acts as a semantic security layer monitoring and filtering both user prompts and model responses to prevent prompt injection, data exfiltration, behavioural manipulation, and adversarial exploitation. As AI capabilities expand, they simultaneously expose new and sophisticated vectors of attack several of which are outlined below.
- Input Manipulation Attack: Attackers craft or alter inputs to coerce an LLM into producing unintended, unsafe, or policy‑violating responses.
- Data Poisoning Attack: Malicious samples injected into training or fine‑tuning data intentionally corrupt model behaviour or degrade performance.
- Model Inversion Attack: Adversaries probe the model to reconstruct sensitive or proprietary information that influenced its training.
- Membership Inference Attack: Attackers query the model to determine whether specific records or examples were included in its training dataset.
- Model Theft: Large‑scale, adaptive querying attempts to replicate a target LLM’s functionality or obtain its proprietary behavior.
- AI Supply Chain Attacks: Compromise of third‑party components (datasets, checkpoints, libraries) that introduces backdoors or integrity failures into the model lifecycle.
- Transfer Learning Attack: Malicious actors exploit fine‑tuning or transfer learning steps to introduce undesirable behaviours into downstream models.
- Model Skewing: Adversarial or biased inputs cause the model’s outputs to drift from expected distributions, undermining reliability and fairness.
- Output Integrity Attack: Attackers manipulate inputs or context to induce fabricated, misleading, or falsified outputs that appear credible.
- Model Poisoning: Crafted updates or poisoned checkpoints inject persistent triggers or failures that remain after deployment.
Traditional security tools such as firewalls, WAFs, and IPS primarily operate at Layers 4 and 7 and are not equipped to detect the semantic and contextual threats posed by large language models (LLMs). Their rule-based mechanisms lack the ability to analyse prompt–response patterns, making them ineffective against attacks like prompt injection, data leakage, and model manipulation.
To address this limitation, a new security paradigm the LLM Firewall is introduced. This architecture is designed to monitor, analyse, and control interactions with generative AI models, offering targeted protection against LLM-specific attack vectors. The following diagram presents its conceptual framework, laying the groundwork for future development and deployment.