The safe operation of drones for commercial and public use presents communication and computational challenges. This article overviews these challenges and describes a prototype system (the Geocast Air Operations Framework, or GAOF) that addresses them using novel network and software architectures.
The full article can be accessed by subscribers at https://www.computer.org/cms/Computer.org/ComputingNow/issues/2016/07/mic2016030068.pdf
Drones, flying devices lacking a human pilot on-board, have attracted major public attention. Retailers would love to be able to deliver goods using drones to save the costs of trucks and drivers; people want to video themselves doing all sorts of athletic and adventuresome activities; and news agencies would like to send drones to capture video of traffic and other news situations, saving the costs of helicopters and pilots.
Today, both technological and legal factors restrict what can be achieved and what can be allowed safely. For example, the US Federal Aviation Administration (FAA) requires drones to operate within line-of-sight (LOS) of a pilot who’s in control, and also requires drones to be registered.
In this article, I will briefly overview some of the opportunities available to improve public and commercial drone operation. I will also discuss a solution approach embodied in a research prototype, the Geocast Air Operations Framework (GAOF), I am working on in AT&T Laboratories Research. This prototype system has been implemented and tested using simulated drones; aerial field testing with real drones is being planned and will be conducted in accordance with the FAA guidelines. The underlying communications platform, the AT&T Labs Geocast System, 1-3 has been extensively field tested in other (non-drone) domains with Earth bound assets, such as people and cars. The goal of the work is to demonstrate a path toward an improved system for the operation of drones, with the necessary secure command and control among all legitimate stakeholders, including drone operator, FAA, law enforcement, and private property owners and citizens. While today there are drones and drone capabilities that work well with one drone operating in an area using a good communication link, there will be increased challenges when there are tens or hundreds of drones in an area.
Note that some classes of drone use are beyond the scope of this discussion:
• Military drones. The US military has been operating drones for many years and are the acknowledged world experts in the field. However, its usage scenarios are quite different, and many of its technical approaches are out of scope for this discussion, because they have resources and authority that are unavailable (such as military frequency bands) or impractical (high-cost drone designs and components) to use in the public/commercial setting. Instead, we seek solutions whose costs are within reason for public and commercial users and which do not require access to resources unavailable to the public.
• Non-compliant drones. It will always be possible for someone to build and fly drones that do not obey the protocols of our system. For example, we will not discuss defense against drones, such as electromagnetic pulse (EMP) weapons, jamming, or trained birds-of-prey.4 However, we hope to work toward a framework for safe and secure large-scale drone use, analogous to establishing traffic laws for cars.
• Drone application-layer issues. Obviously, drones should actually do something useful once we have gone to the trouble to operate them safely. Often, this takes the form of capturing video or gathering other sensor data. This article does not address the issues involved in transferring large data sets from drone to ground or drone to cloud.
The rest of this article will give background on the communications system underlying the GAOF, the challenges of safe and scalable air operations, and how the GAOF addresses these challenges.
Modern software-based services are implemented as distributed systems with complex behavior and failure modes. Chaos engineering uses experimentation to ensure system availability. Netflix engineers have developed principles of chaos engineering that describe how to design and run experiments.
THIRTY YEARS AGO, Jim Gray noted that “A way to improve availability is to install proven hardware and software, and then leave it alone.”1 For companies that provide services over the Internet, “leaving it alone” isn’t an option. Such service providers must continually make changes to increase the service’s value, such as adding features and improving performance. At Netflix, engineers push new code into production and modify runtime configuration parameters hundreds of times a day. (For a look at Netflix and its system architecture, see the sidebar.) Availability is still important; a customer who can’t watch a video because of a service outage might not be a customer for long.
But to achieve high availability, we need to apply a different approach than what Gray advocated. For years, Netflix has been running Chaos Monkey, an internal service that randomly selects virtualmachine instances that host our production services and terminates them.2 Chaos Monkey aims to encourage Netflix engineers to design software services that can withstand failures of individual instances. It’s active only during normal working hours so that engineers can respond quickly if a service fails owing to an instance termination.
Chaos Monkey has proven successful; today all Netflix engineers design their services to handle instance failures as a matter of course.
That success encouraged us to extend the approach of injecting failures into the production system to improve reliability. For example, we perform Chaos Kong exercises that simulate the failure of an entire Amazon EC2 (Elastic Compute Cloud) region. We also run Failure Injection Testing (FIT) exercises in which we cause requests between Netflix services to fail and verify that the system degrades gracefully.3 Over time, we realized that these activities share underlying themes that are subtler than simply “break things in production.” We also noticed that organizations such as Amazon,4 Google,4 Microsoft,5 and Facebook6 were applying similar techniques to test their systems’ resilience. We believe that these activities form part of a discipline that’s emerging in our industry; we call this discipline chaos engineering. Specifically, chaos engineering involves experimenting on a distributed system to build confidence in its capability to withstand turbulent conditions in production. These conditions could be anything from a hardware failure, to an unexpected surge in client requests, to a malformed value in a runtime configuration parameter. Our experience has led us to determine principles of chaos engineering (for an overview, see http://principlesofchaos .org), which we elaborate on here.
This article is obtained from http://spectrum.ieee.org/cars-that-think/transportation/self-driving/fatal-tesla-autopilot-crash-reminds-us-that-robots-arent-perfect?utm_campaign=TechAlert_07-21-16&utm_medium=Email&utm_source=TechAlert&bt_alias=eyJ1c2VySWQiOiAiOWUzYzU2NzUtMDNhYS00YzBjLWIxMTItMWUxMjlkMjZhNjE0In0%3D
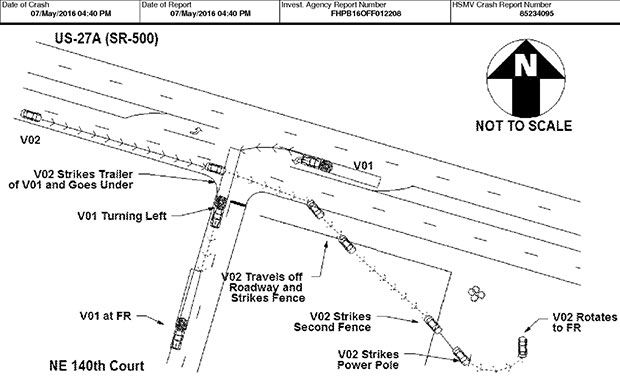
On 7 May, a Tesla Model S was involved in a fatal accident in Florida. At the time of the accident, the vehicle was driving itself, using its Autopilot system. The system didn’t stop for a tractor-trailer attempting to turn across a divided highway, and the Tesla collided with the trailer. In a statement, Tesla Motors said this is the “first known fatality in just over 130 million miles [210 million km] where Autopilot was activated” and suggested that this ratio makes the Autopilot safer than an average vehicle. Early this year, Tesla CEO Elon Musk told reporters that the Autopilot system in the Model S was “probably better than a person right now.”
The U.S. National Highway Transportation Safety Administration (NHTSA) has opened a preliminary evaluation into the performance of Autopilot, to determine whether the system worked as it was expected to. For now, we’ll take a closer look at what happened in Florida, how the accident may could have been prevented, and what this could mean for self-driving cars.
According to an official report of the accident, the crash occurred on a divided highway with a median strip. A tractor-trailer truck in the westbound lane made a left turn onto a side road, making a perpendicular crossing in front of oncoming traffic in the eastbound lane. The driver of the truck didn’t see the Tesla, nor did the self-driving Tesla and its human occupant notice the trailer. The Tesla collided with the truck without the human or the Autopilot system ever applying the brakes. The Tesla passed under the center of the trailer at windshield height and came to rest at the side of the road after hitting a fence and a pole.
Image: Florida Highway Patrol
Tesla’s statement and a tweet from Elon Musk provide some insight as to why the Autopilot system failed to stop for the trailer. The autopilot relies on cameras and radar to detect and avoid obstacles, and the cameras weren’t able to effectively differentiate “the white side of the tractor trailer against a brightly lit sky.” The radar should not have had any problems detecting the trailer, but according to Musk, “radar tunes out what looks like an overhead road sign to avoid false braking events.”
We don’t know all the details of how the Tesla S’s radar works, but the fact that the radar could likely see underneath the trailer (between its front and rear wheels), coupled with a position that was perpendicular to the road (and mostly stationary) could easily lead to a situation where a computer could reasonably assume that it was looking at an overhead road sign. And most of the time, the computer would be correct.
Tesla’s statement also emphasized that, despite being called “Autopilot,” the system is assistive only and is not intended to assume complete control over the vehicle:
It is important to note that Tesla disables Autopilot by default and requires explicit acknowledgement that the system is new technology and still in a public beta phase before it can be enabled. When drivers activate Autopilot, the acknowledgment box explains, among other things, that Autopilot “is an assist feature that requires you to keep your hands on the steering wheel at all times,” and that “you need to maintain control and responsibility for your vehicle” while using it. Additionally, every time that Autopilot is engaged, the car reminds the driver to “Always keep your hands on the wheel. Be prepared to take over at any time.” The system also makes frequent checks to ensure that the driver’s hands remain on the wheel and provides visual and audible alerts if hands-on is not detected. It then gradually slows down the car until hands-on is detected again.
I don’t believe that it’s Tesla’s intention to blame the driver in this situation, but the issue (and this has been an issue from the beginning) is that it’s not entirely clear whether drivers are supposed to feel like they can rely on the Autopilot or not. I would guess Tesla’s position on this would be that most of the time, yes, you can rely on it, but because Tesla has no idea when you won’tbe able to rely on it, you can’t really rely on it. In other words, the Autopilot works very well under ideal conditions. You shouldn’t use it when conditions are not ideal, but the problem with driving is that conditions can very occasionally turn from ideal to not ideal almost instantly, and the Autopilot can’t predict when this will happen. Again, this is a fundamental issue with any car that has an “assistive” autopilot that asks for a human to remain in the loop, and is why companies like Google have made their explicit goal to remove human drivers from the loop entirely.
The fact that this kind of accident has happened once means that there is a reasonable chance that it, or something very much like it, could happen again. Tesla will need to address this, of course, although this particular situation also suggests ways in which vehicle safety in general could be enhanced.
Here are a few ways in which this accident scenario could be addressed, both by Tesla itself, and by lawmakers more generally:
A Tesla Software Fix: It’s possible that Tesla’s Autopilot software could be changed to more reliably differentiate between trailers and overhead road signs, if it turns out that that was the issue. There may be a bug in the software, or it could be calibrated too heavily in favor of minimizing false braking events.
A Tesla Hardware Fix: There are some common lighting conditions in which cameras do very poorly (wet roads, reflective surfaces, or low sun angles), and the resolution of radar is relatively low. Almost every other self-driving car with a goal of sophisticated autonomy uses LIDAR to fill this kind of sensor gap, since LIDAR provides high resolution data out to a distance of several hundred meters with much higher resiliency to ambient lighting effects. Elon Musk doesn’t believe that LIDAR is necessary for autonomous cars, however:
For full autonomy you’d really want to have a more comprehensive sensor suite and computer systems that are fail proof.
That said, I don’t think you need LIDAR. I think you can do this all with passive optical and then with maybe one forward RADAR… if you are driving fast into rain or snow or dust. I think that completely solves it without the use of LIDAR. I’m not a big fan of LIDAR, I don’t think it makes sense in this context.
Musk may be right, but again, almost every other self-driving car uses LIDAR. Virtually every other company trying to make autonomy work has agreed that the kind of data that LIDAR can provide is necessary and unique, and it does seem like it might have prevented this particular accident, and could prevent accidents like it.
Vehicle-to-Vehicle Communication: The NHTSA is currently studying vehicle-to-vehicle (V2V) communication technology, which would allow vehicles “to communicate important safety and mobility information to one another that can help save lives, prevent injuries, ease traffic congestion, and improve the environment.” If (or hopefully when) vehicles are able to tell all other vehicles around them exactly where they are and where they’re going, accidents like these will become much less frequent.
Side Guards on Trailers: The U.S. has relatively weak safety regulations regarding trailer impact safety systems. Trailers are required to have rear underride guards, but compared with other countries (like Canada), the strength requirements are low. The U.S. does not require side underride guards. Europe does, but they’re designed to protect pedestrians and bicyclists, not passenger vehicles. An IIHS analysis of fatal crashes involving passenger cars and trucks found that “88 percent involving the side of the large truck… produced underride,” where the vehicle passes under the truck. This bypasses almost all front-impact safety systems on the passenger vehicle, and as Tesla points out, “had the Model S impacted the front or rear of the trailer, even at high speed, its advanced crash safety system would likely have prevented serious injury as it has in numerous other similar incidents.”
If Tesla comes up with a software fix, which seems like the most likely scenario, all other Tesla Autopilot systems will immediately benefit from improved safety. This is one of the major advantages of autonomous cars in general: accidents are inevitable, but unlike with humans, each kind of accident only has to happen once. Once a software fix has been deployed, no Tesla autopilot will make this same mistake ever again. Similar mistakes are possible, but as Tesla says, “as more real-world miles accumulate and the software logic accounts for increasingly rare events, the probability of injury will keep decreasing.”
The near infinite variability of driving on real-world roads full of unpredictable humans means that it’s unrealistic to think that the probability of injury while driving, even if your car is fully autonomous, will ever reach zero. But the point is that autonomous cars, and cars with assistive autonomy, are already much safer than cars driven by humans without the aid of technology. This is Tesla’s first Autopilot-related fatality in 130 million miles [210 million km]: humans in the U.S. experience a driving fatality on average every 90 million miles [145 million km], and in the rest of the world, it’s every 60 million miles [100 million km]. It’s already far safer to have these systems working for us, and they’re only going to get better at what they do.
See more at: http://www.planetbiometrics.com/article-details/i/4716/desc/henna-delays-fingerprint-secured-graduations-in-india/#sthash.3GbIo1wv.dpuf
Students hoping to graduate from an educational course in India have had to wait to confirm final results as henna applied to their fingers disrupted a biometric authentication tool. The biometric device rejected the thumb impressions of “scores” of female candidates who applied “Mehendi” traditional henna makeup during the Eid festival in the city of Hyderabad, reported Sisat. With only couple of days are left for completion of the verification process which escalated students’ anxiety, girls were seen trying to erase the mehendi with the help of detergent and even hydrogen peroxide. An official said that clear instructions on the matter were provided during the time of application, but the girls didn’t take it seriously. He said that light coloured henna were able to match using the, but the dark colours were not recognised. Students were asked not to panic as they have until later this week to provide verification details. – See more at: http://www.planetbiometrics.com/article-details/i/4716/desc/henna-delays-fingerprint-secured-graduations-in-india/#sthash.3GbIo1wv.dpuf
Clouds are powerful change‐agents and enablers. Several converging and complementary factors are driving the rise of cloud computing. The increasing maturity of cloud technologies and cloud service offerings coupled with users’ greater awareness of the cloud’s benefits (and limitations) is accelerating the cloud’s adoption. Better Internet connectivity, intense competition among cloud service providers (CSPs), and digitalization of enterprises, particularly micro‐, small‐, and medium‐sized businesses, are increasing the clouds’ use.
Cloud computing is changing the way people and enterprises use computers and their work practices, as well as how companies and governments deploy their computer applications. It will drastically improve access to information for all as well as cut IT costs. It redefines not only the information and communication technology (ICT) industry but also enterprise IT in all industry and business sectors. It is also driving innovations by small enterprises and facilitating deployment of new applications that would otherwise be infeasible.
The introduction of new cloud computing platforms and applications, and the emergence of open standards for cloud computing will boost cloud computing’s appeal to both cloud providers and users. Furthermore, clouds will enable open‐source and freelance developers to deploy their applications in the clouds and profit from their developments. As a result, more open‐source software will be published in the cloud. Clouds will also help close the digital divide prevalent in emerging and underdeveloped economies and may help save our planet by providing a greener computing environment.
Cloud Ecosystem
In order to embrace the cloud successfully and harness its power for traditional and new kinds of applications, we must recognize the features and promises of one or more of the three foundational cloud services – software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS). We must also understand and properly address other aspects such as security, privacy, access management, compliance requirements, availability, and functional continuity in case of cloud failure. Furthermore, adopters need to learn how to architect cloud‐based systems that meet their specific requirements. We may have to use cloud services from more than one service provider, aggregate those services, and integrate them on premises’ legacy systems or applications.
To assist cloud users in their transition to the cloud, a broader cloud ecosystem is emerging that aims to offer a spectrum of new cloud support services to augment, complement, or assist the foundational SaaS, IaaS, and PaaSofferings. Examples of such services are security as a service, identity management as a service, and data as a service. Investors, corporations, and startups are eagerly investing in promising cloud computing technologies and services in developed and developing countries. Many startups and established companies continue to enter into the cloud arena offering a variety of cloud products and services, and individuals and businesses around the world are increasingly adopting cloud‐based applications. Governments are promoting cloud adoption, particularly among micro, small, and medium enterprises. Thus, a new larger cloud ecosystem is emerging.
Addressing the Challenges and Concerns
While hailing the features of existing and emerging new cloud services that help users adopt and tailor the services they use according to their needs, it is important to recognize that the cloud ecosystem still presents a few challenges and concerns. Such concerns are those relating to performance interoperability, the quality of service of the entire cloud chain, compliance with regulatory requirements and standards, security and privacy of data, access control and management, trust, and service failures and their impact. All these issues need to be addressedinnovatively, and this calls for collaboration among various players in the cloud ecosystem.
Good news is that investors, established corporations, and startups are eagerly investing in promising cloud computing technologies and services, and are willing to collaborate (to an extent) to raise the clouds to newer heights. We can hope for a brighter, bigger, more collaborative cloud ecosystem that benefits all of its stakeholders and society at large. Cloud service providers, the IT industry, professional and industry associations, governments, and IT professionals all have a role to play in shaping, fostering, and harnessing the full potential of the emerging cloud ecosystem.
Gaining Cloud Computing Knowledge
To better understand and exploit the potential of the cloud – and to advance the cloud further – practitioners, IT professionals, educators, researchers, and students need an authoritative knowledge source that comprehensively and holistically covers all aspects of cloud computing.
Several books on cloud computing are now available but none of them cover all key aspects of cloud computing comprehensively and meet the information needs of IT professionals, academics, researchers, and undergraduate and postgraduate students. To gain a holistic view of the cloud, one has to refer to a few different books, which is neither convenient nor practicable.
The new Encyclopedia of Cloud Computing, edited by us and published by IEEE Computer Society and Wiley this month, serves this need. It contains a wealth of information for those interested in understanding, using, or providing cloud computing services; for developers and researchers who are interested in advancing cloud computing and businesses, and for individuals interested in embracing and capitalizing on the cloud. In this encyclopedia, we offer a holistic and comprehensive view of the cloud from different perspectives.
Caterpillar Safety Systems has partnered with Seeing Machines to install fatigue protection software in thousands of mining trucks. According to a Huffington Post report, the software uses a camera, speaker and light system to measure signs of fatigue – for instance eye closure and head position. When a potential fatigue event is detected, the system sounds an alarm and sends a video clip of the driver to a 24-hour sleep fatigue center at Caterpillar headquarters, the report adds.
Don’t forget to click the links because they come with useful information.
Why A Mining Company Is Getting Into Face Recognition Software
Drowsy driving is notoriously tough to detect. There’s no test to prove it, the way a breathalyzer can prove someone was driving drunk. But technology to detect drowsy driving is in the works.
In commercial transport, one industry is leading the way: mining. The stakes are particularly high in this field since the enormous haul trucks used in mining are several times the height of a person. Imagine dozing off at the wheel of one of these.
Caterpillar Safety Services, a consultancy branch of the global mining company, has partnered with the tech company Seeing Machines to put fatigue detection software in thousands of mining trucks around the world. The software uses a camera, speaker and light system to measure signs of fatigue like eye closure and head position. When a potential “fatigue event” is detected, the system sounds an alarm in the truck and sends a video clip of the driver to a 24-hour “sleep fatigue center” at Caterpillar headquarters in Peoria, Illinois.
At that point, a safety advisor contacts them via radio, notifies their site manager, and sometimes recommends a sleep intervention.
“This system automatically scans for the characteristics of microsleep in a driver,” Sal Angelone, a fatigue consultant at the company, told The Huffington Post, referencing the brief, involuntary pockets of unconsciousness that are highly dangerous to drivers. “But this is verified by a human working at our headquarters in Peoria.”
Caterpillar has a four-year license from Seeing Machines to manufacture the software. For now, it’s the exclusive provider of this technology within the mining industry. Some 5,000 vehicles ― a combination of Caterpillar’s own trucks and those of other mining companies ― carry the equipment. There are about 38,000 haul trucks worldwide, by Caterpillar’s estimate, so the fatigue-detecting trucks are still a small fraction of that, but Caterpillar hopes to eventually equip all of them.
When a “fatigue event” is recorded, it’s up to the mining site to recommend a course of action to the driver, or vice versa. Last month in Nevada, for instance, a mining truck driver had three fatigue events within four hours; he was contacted onsite and essentially forced to take a nap. Last February in North Carolina, one night shift truck driver who experienced a fatigue event realized it was a sign of an underlying sleep disorder and asked his site management for medical assistance. (Caterpillar has mining operations globally from China to Canada).
“It’s not unusual for someone to lose their frame of reference of what is normal in regard to fatigue,” said Angelone. This may be because miners’ shift work goes against typical human circadian rhythms. A driver’s shift is either eight or twelve hours long, said Angelone, but those shifts can occur during the middle of the night, late afternoon or any other time.
“Many sites run a 24/7 operation,” he said. “These drivers are not always sleeping through the night.”
In the past year, since the company started recording fatigue events last July, it has recorded about 600 instances, said Angelone. He said this constitutes a stunning 80 percent reduction in fatigue events from previous years.
The biggest reason for this, said Angelone, is that once an alarm goes off in a truck, the driver becomes much more aware of their fatigue, and is more cautious and proactive about drowsy driving than they would be otherwise.
These results invite the question of why fatigue detection software has not yet reached consumer vehicles.
One explanation is that the car industry has not been slow to embrace the technology, but that commercial trucking has been particularly fast.
“There is a lot of incentive to improve safety in our industry,” said Tim Crane, general manager of Caterpillar Safety Services. “Our vehicles are huge and pose unique challenges, so the government really wants to see that we’re trying.”
Crane expects the use of fatigue detection technology in consumer cars to increase “exponentially” in the next few years. Jeremy Terpstra of Seeing Machines echoed the sentiment.
“We have arrangements with many different car manufacturers,” he said. “It’s only a matter of time before this technology is in all vehicles, everywhere.”
Michael Vögler and Johannes M. Schleicher of Technische Universität Wien
Christian Inzinger of University of Zurich
Schahram Dustdar of Technische Universität Wien
Rajiv Ranjan of Newcastle University
Smart city” has emerged as an umbrella term for the pervasive implementation of information and communication technologies (ICT) designed to improve various areas of today’s cities. Areas of focus include citizen well-being, infrastructure, industry, and government. Smart city applications operate in a dynamic environment with many stakeholders that not only provide data for applications, but can also contribute functionality or impose (possibly conflicting) requirements. Currently, the fundamental stakeholders in a smart city are energy and transportation providers, as well as government agencies, which offer large amounts of data about certain aspects (for example, public transportation) of a city and its citizens.
Increasingly, stakeholders deploy connected Internet of Things (IoT) devices that deliver large amounts of near-real-time data and can enact changes in the physical environment. Efficient management of these large volumes of data is challenging, especially since data gathered by IoT devices might have critical security and privacy requirements that must be honored at all times. Nevertheless, this presents a significant opportunity to closely integrate stakeholders and data from different domains to create new applications that can tackle the increasingly complex challenges of today’s cities, such as autonomous traffic management, efficient building management, and emergency response systems.
Currently, smart city applications are usually deployed on premises. Cloud computing has matured to a point where practitioners are increasingly comfortable with migrating their existing smart city applications to the cloud to leverage its benefits (such as dynamic resource provisioning and cost savings). However, future smart city applications must also be able to operate across cities to create a global, interconnected system of systems for the future Internet of Cities.1 Therefore, such applications have to be designed, implemented, and operated as cloud-native applications, allowing them to elastically respond to changes in request load, stakeholder requirements, and unexpected changes in the environment.
Here, we outline our recent work on the smart city operating system (SCOS), a central element of future smart city application ecosystems. The SCOS is designed to resemble a modern computer operating system, providing unified abstractions for underlying resources and management tasks, but specifically tailored to city scale. We present the specific foundations of SCOS that enable a larger smart city application ecosystem,2 allowing stakeholders and citizens to create applications within the smart city domain. This approach enables them to build applications by only focusing on their specific demand, while completely freeing them from the complexities and problems they’re currently facing.
Read more at https://www.computer.org/cms/Computer.org/ComputingNow/issues/2016/07/mcd2016020072.pdf
When your company will start to grow and you will earn more profits, you will have to come up with new strategies. If you have developed a large company then you will need the things that will help you manage the whole business and to do so, you will require a software to manage the projects you are running. To manage these projects, we are going to share few things that will help you in getting the right software. Project management software will become your need if you are developed into a big company. Here are few things that you need to pay attention to so you can choose the right software for your company.
Evaluating the right things
First of all, you need to be sure that you are well aware of your needs and you are going to choose the project management software after paying attention to your company’s needs. You can come up with something like Celoxis.com tools for online project management. If you are working online and managing your employees online then you should consider getting a software that is best for online project management. Your evaluation process will include so many things andyou need to be sure that you are choosing the right product according to your needs. If you have selected the design and you really like the functionality of the software too then you need to be sure that you are going with that option. However, if you need to add few things to it then you need to get it tailored according to your needs so your employees can get the benefits from it.
Software support and security
Make it sure that you are selecting the software that has a great support from its developers and provides a great security. Security is something that you need to put on the first priority and you need to be sure that you are choosing the best quality software that comes with a lifetime support. If there is any fault in the software and you are unable to resolve it then you should contact the support center so they can provide you the fix for it. Same goes for the security and you need to be sure that all of your data is secured properly.
A spec is short for “specification”. A spec is something that describes what a piece of software should do.
For the moment I am being deliberately broad and inclusive. If you are experienced in software project management, you probably have something very specific in mind when think of the words “spec” or “requirement”. In fact, it is possible that you are not willing to acknowledge that something is a spec unless it matches up fairly well with your image of same. That’s okay. Just stay with me.
For now, I’m saying that anything that is a “description of what a piece of software should do” can be considered a spec. This may include:
A document
A bunch of 3×5 note cards
A spreadsheet containing a list of features
I am currently involved in a project where my role is “The Walking Spec”. In other words, I am the person who mostly knows everything about how this piece of software should mostly behave. When people need a spec, they ask me a question (footnote 2). I’m not saying that I am a good spec, but I don’t think I’m the worst spec I have ever seen, and I am certainly better that no spec at all. 🙂
Seriously, a spec needs to be in a form which is accessible to more than one person. It needs to be written down, either in a computer or on paper.
But how?
…..
on another note Eric Sink wrote:
Changing Requirements
If a project gets all the way to completion with bad requirements, the likelihood is that the software will be disappointing. When this happens, the resulting assignment-of-blame exercise can be fun to watch. From a safe distance.
More often, during the project somebody notices a problem with the requirements and changes them along the way.
Marketing: By the way, I forgot to mention that the application has to be compatible with Windows 95.
Development: Windows 95? You’re kidding, right? People stopped using Win95 over a decade ago!
Marketing: Oh, and Mac OS 7.6 too.
Development: What? We’re building this app with .NET 3.0 and we’re already 40% done!
Marketing: You’re half done? That’s great! Oh, and I forgot to mention we need compatibility with the Atari ST.
Development: Why didn’t you tell us this before we started?
Marketing: Sorry. I forgot. It’s no problem to change it now, right?
Changing requirements mid-project can be expensive and painful.
However, it is very rare to have a project where all the requirements are known and properly expressed before development begins. So, it behooves us to prepare for changes. If we choose a development process which rigidly requires a perfect spec before construction can begin, we are just setting ourselves up for pain. We need to be a bit more agile.
Wide variations remain in the average distance between electric car charge points, with some drivers facing distances of up to 47 miles (76km).
North Devon has the longest average distances between public charging points, according to Department for Transport statistics.
The RAC said there was “some way to go” before users would be cured of “range anxiety”.
The average distance between charging points in England was 3.8 miles (6km).
It compares with an average distance between petrol and diesel filling stations of one mile.
In North Devon, the average distance between public charging points can be between 18 and 47 miles. Barrow-in-Furness in Cumbria has average distances of up to 37 miles (60km).
The RAC says the furthest distance between petrol stations in the UK is 19 miles, for drivers in Applecross, West Scotland.
Rise in use
According to the Society of Motor Manufacturers and Traders, 17,000 hybrid and electric cars left UK showrooms in March 2016, compared with 1,354 in the same month in 2006.
Go Ultra Low, the joint government and car industry campaign to get drivers to switch to electric vehicles, said year-on-year sales were up 23%, with more than 115 electric cars registered every day in the first quarter of 2016, equivalent to one every 13 minutes.
Charging vs fuelling
3,904 UK public charging point locations
8,500 UK filling stations
1 mile average distance between filling stations
3.8 miles average distance between charging points