It’s 2 AM. A student is staring at a folder full of lecture slides, project guidelines, and 80-page PDFs. They have a specific question: “What are the submission requirements for Project Phase 1?” They know the answer is somewhere in those files, but where?
We’ve all been there. As an educator, I see this problem all the time. Students have the materials, but information retrieval is a huge, unaddressed challenge.
So, I asked myself: “What if I could build a 24/7 AI teaching assistant for each of my courses? One that only knows about that specific course’s materials?”
That’s exactly what I did. The result is a lightweight, custom-built, multi-course AI chatbot. Here’s how I built it.
The “Aha!” Moment: Why Not Just Use ChatGPT?
The first question is obvious: “Why not just use an off-the-shelf AI?”
The simple answer: No public AI knows about my private course materials. I can’t ask it about the “SBEG3163 System Analysis” syllabus or the “MBEX1013 Research Methodology” project guide.
The solution is a framework called Retrieval-Augmented Generation (RAG).
In plain English, RAG means we “teach” the AI by giving it a cheat sheet before it answers. The process is simple:
- Retrieve: When a student asks a question, we first search our own documents (the cheat sheet) for the most relevant text.
- Augment: We take that relevant text and paste it into a prompt for the AI.
- Generate: We tell the AI, “Using only this text I just gave you, answer the student’s question.”
This gives us the power of a giant AI like Google’s Gemini, but grounded in the specific, factual knowledge of our own private materials.
The “Franken-Stack”: Simple, Powerful Tech
I didn’t want a heavy, expensive, complicated system. I wanted something that could run on any basic web host. So, I built a “vanilla” stack that is surprisingly powerful:
- Frontend: Simple, “vanilla” HTML, CSS, and JavaScript. No React, no Vue. Just
chat.jsand afetch()call. - Backend: Good ol’ PHP (
api.php). Why? Because it’s everywhere, it’s simple, and it’s perfect for acting as a middle-man. - The “Brain”: The Google Gemini API. We send our RAG prompt to it, and it generates the human-like answer.
- The “Database”: A folder of JSON files (
knowledge/). This “NoDB” approach means there’s no complex database to set up. Each course gets its owncourse_code.jsonfile.
How It Works: The Two-Part System
The whole project is split into two distinct parts:
Part 1: The “Librarian” (Offline Indexing)
Before the chatbot can answer questions, someone has to read all the books. This is our indexer.php script.
This is a password-protected admin page I run one time after I upload new materials. It:
- Scans the
materials/folder for all course sub-folders (likematerials/mbex1013/). - Reads all the
.pdfand.docxfiles inside. - Parses & Chunks all the text into small, overlapping paragraphs.
- Saves everything into a single, clean JSON file (e.g.,
knowledge/mbex1013.json).
This knowledge/ folder becomes our “library,” and the JSON files are the “index cards” for our AI.
Part 2: The “Concierge” (Real-time Chat)
This is what happens when a student asks a question.
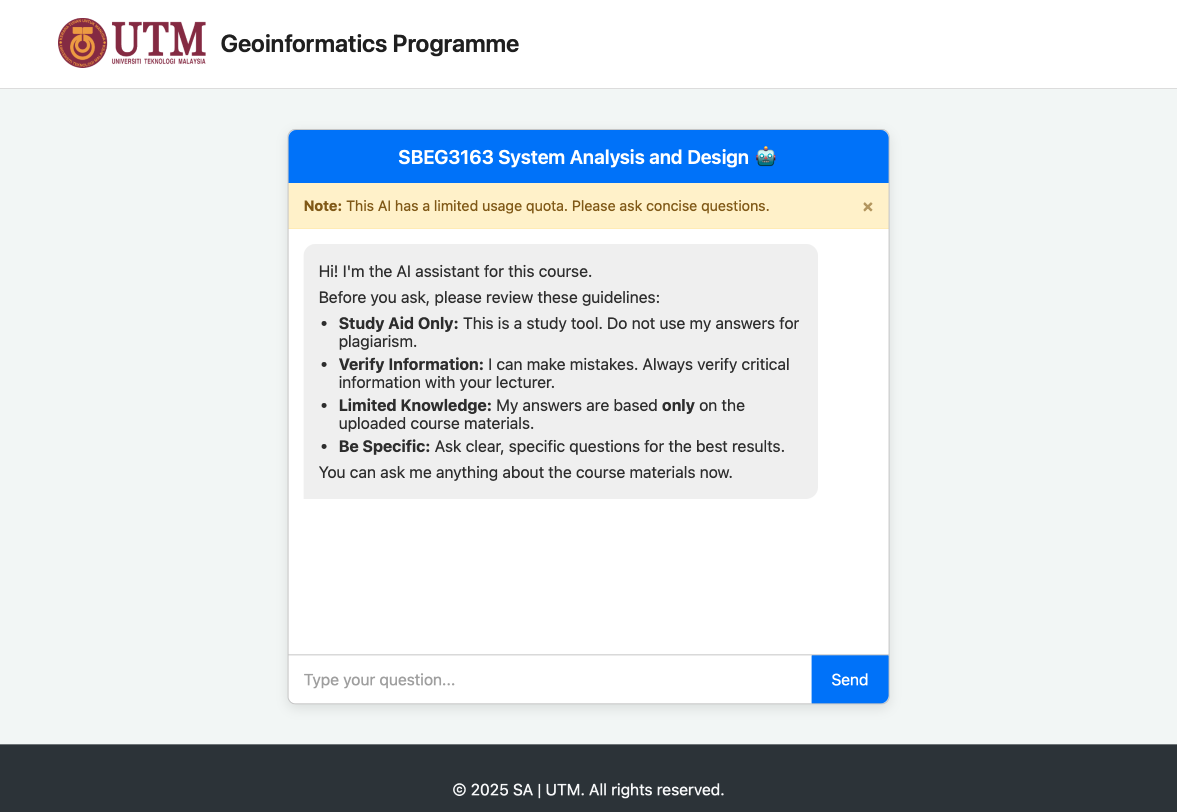
- A student clicks on the “Research Methodology” card on our landing page. This sends them to
chat.html?course=mbex1013. - The
chat.jsscript on that page grabs thecoursecode from the URL. - The student asks, “What is a literature review?”
chat.jssends afetchrequest to our backend:api.php.api.phpwakes up. It sees the course codembex1013and loads onlyknowledge/mbex1013.json.- It searches this file for the most relevant chunks of text related to “literature review.”
- It builds a big prompt for Google’s AI: “Hey Gemini, using this text about literature reviews […], please answer the student’s question.”
- Gemini sends back a perfect, HTML-formatted answer.
api.phppasses that answer back to the student’s browser.- The answer appears in the chat box.
The entire process takes about 2-3 seconds.
The Secret Sauce: Keeping Courses Separate
The most important feature is that the “Research Methodology” bot knows nothing about “System Analysis.” The knowledge is strictly siloed.
This is achieved by that simple URL parameter (?course=...). The api.php script is a “dumb” (but smart!) bouncer. It only loads the single JSON file it’s told to. This prevents “cross-contamination” and ensures students get relevant, accurate answers for the one course they are asking about.
What I Learned (The Good and The Bad)
- The Good: It works! It’s fast, incredibly cheap (basic PHP hosting and pay-as-you-go API calls), and fully custom. I have 100% control over the UI, the prompts, and the data.
- The Bad (Limitation 1): The indexing is manual. If I update a PDF, I have to remember to go to
indexer.phpand run it again. The next step is to automate this with a cron job. - The Bad (Limitation 2): My search is basic (keyword matching). A “smarter” bot would use vector embeddings (a way to search by meaning, not just keywords). This is the next major upgrade.
See It Live!
I’m a big believer in building simple tools that solve real problems. This project went from an idea to a deployed, working tool in just a few days.
You can see the live project, fully functional, right here: https://dev.kstutm.com/chatbot/
Feel free to click on a course and ask it a question! (Just remember, it only knows what’s in the materials I gave it).
